K Nearest Neighbors
Autor: Laura Moldovan, AIIS x Nitro AI Workshops 2025
Rezolvă în Colab: K Nearest Neighbors
Slide-uri: KNN Slides
1.1 Cum funcționează KNN?
KNN este un algoritm de învățare supervizată bazat pe principiul că obiecte similare tind să fie apropiate unul de celălalt în spațiul caracteristicilor. Procesul de clasificare urmează pașii:
-
Pentru un punct nou de clasificat:
- Se calculează distanța față de toate punctele din setul de antrenare
- Se selectează K cei mai apropiați vecini
- Se atribuie clasa majoritară dintre acești vecini
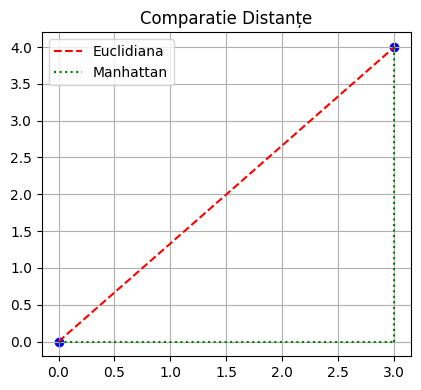
1.2 Tipuri de Distanțe
În KNN, modul în care măsurăm "apropierea" este crucial. Cele mai comune tipuri de distanțe sunt:
-
Distanța Euclidiană:
- Formula: d = \sqrt{\sum(xi - yi)²}
- Cea mai comună și intuitivă
- Bună pentru spații continue
-
Distanța Manhattan:
- Formula: d = ∑|xi - yi|
- Utilă în spații discrete sau grid-uri
- Cunoscută și ca distanța "city block"
-
Distanța Minkowski:
- O generalizare a distanțelor Euclidiană și Manhattan
- Formula: d = (\sum|xi - yi|^p)^\frac{1}{p}
- p=2 pentru Euclidiană, p=1 pentru Manhattan
-
Similaritatea Cosinus:
- Măsoară unghiul dintre vectori
- Utilă pentru date de înaltă dimensionalitate
def plot_distances():
# Cream puncte pentru exemplu
point1 = np.array([0, 0])
point2 = np.array([3, 4])
# Plotam punctele
plt.figure(figsize=(12, 4))
# Distanța Euclidiana
plt.subplot(131)
plt.plot([point1[0], point2[0]], [point1[1], point2[1]], 'r--', label='Euclidiana')
plt.plot([point1[0], point2[0]], [point1[1], point1[1]], 'g:', label='Manhattan')
plt.plot([point2[0], point2[0]], [point1[1], point2[1]], 'g:')
plt.scatter([point1[0], point2[0]], [point1[1], point2[1]], c='blue')
plt.title('Comparatie Distanțe')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
# Vizualizam distantele
plot_distances()
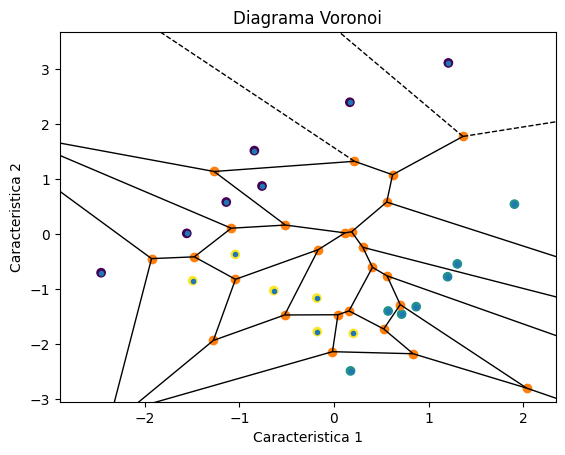
1.3 Diagrame Voronoi
Diagramele Voronoi sunt un concept fundamental pentru înțelegerea KNN. Acestea împart spațiul în regiuni în funcție de proximitatea față de punctele de antrenare.
# Cream o functie pentru a vizualiza diagrama Voronoi pentru un set simplu de date
def plot_voronoi():
# Generam date simple
X, y = make_classification(n_samples=20, n_features=2, n_redundant=0,
n_clusters_per_class=1, n_classes=3)
# Cream diagrama Voronoi
vor = Voronoi(X)
# Plotam rezultatul
plt.figure(figsize=(10, 6))
voronoi_plot_2d(vor)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='viridis')
plt.title('Diagrama Voronoi')
plt.xlabel('Caracteristica 1')
plt.ylabel('Caracteristica 2')
plt.show()
# Vizualizam diagrama Voronoi
plot_voronoi()
<Figure size 1000x600 with 0 Axes>
2. Încărcarea și Pregătirea Datelor
Vom folosi setul de date Iris, care conține măsurători pentru trei specii diferite de flori Iris. Acest set de date este perfect pentru începători deoarece este simplu și ușor de înțeles.
#Importarea librariilor necesare
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris, make_classification
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, classification_report
import seaborn as sns
from scipy.spatial import Voronoi, voronoi_plot_2d
# Incarcam setul de date Iris
iris = load_iris()
X = iris.data
y = iris.target
# Cream un DataFrame pentru o vizualizare mai buna a datelor
df = pd.DataFrame(X, columns=iris.feature_names)
df['specie'] = pd.Categorical.from_codes(y, iris.target_names)
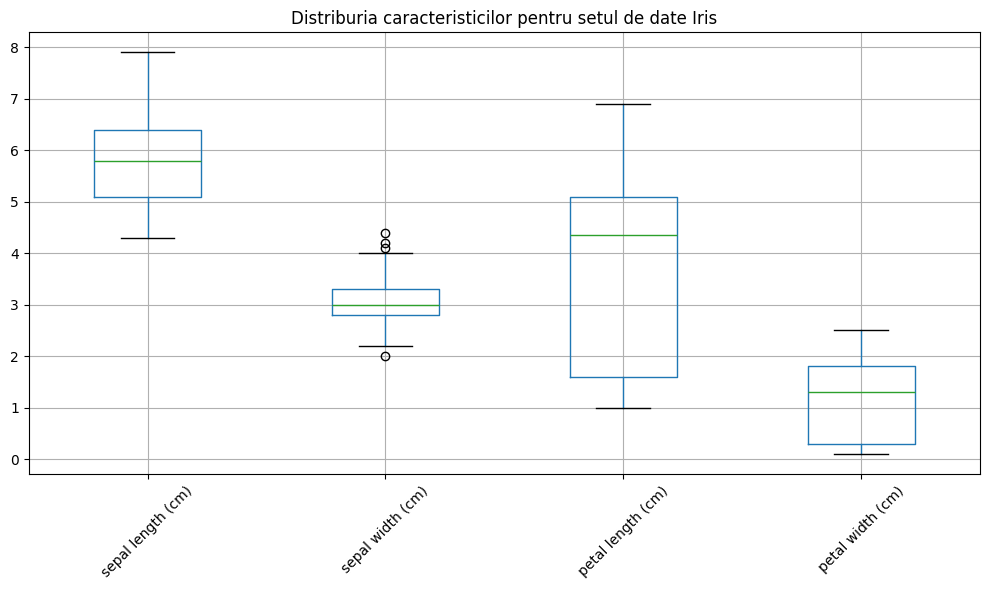
3. Vizualizarea Datelor
Să înțelegem mai întâi datele noastre prin câteva vizualizări simple.
print("Primele 5 randuri din setul nostru de date:")
print(df.head())
# Cream o vizualizare a distributiei caracteristicilor
plt.figure(figsize=(10, 6))
df.boxplot(column=iris.feature_names)
plt.title('Distriburia caracteristicilor pentru setul de date Iris')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
Primele 5 randuri din setul nostru de date:
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) \
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
specie
0 setosa
1 setosa
2 setosa
3 setosa
4 setosa
4. Împărțirea Datelor
Împărțim datele în set de antrenare și set de testare. Setul de antrenare va fi folosit pentru a antrena modelul, iar setul de testare pentru a evalua performanța modelului pe date noi, nevăzute.
# Impartim datele in set de antrenare și set de testare
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(f"Dimensiune set de antrenare: {X_train.shape}")
print(f"Dimensiune set de testare: {X_test.shape}")
Dimensiune set de antrenare: (120, 4)
Dimensiune set de testare: (30, 4)
5. Antrenarea Modelului KNN
Acum vom crea și antrena modelul nostru KNN. Vom începe cu K=3 (vom lua în considerare cei mai apropiați 3 vecini).
# Cream și antrenam modelul
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
KNeighborsClassifier(n_neighbors=3)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
KNeighborsClassifier(n_neighbors=3)
6. Evaluarea Modelului
Vom face predicții pe setul de validare și vom evalua performanța modelului
# Facem predictii
y_pred = knn.predict(X_test)
# Calculam acuratetea
accuracy = accuracy_score(y_test, y_pred)
print(f"\nAcuratete: {accuracy:.2f}")
# Afisam raportul detaliat de clasificare
print("\nRaport de clasificare:")
print(classification_report(y_test, y_pred, target_names=iris.target_names))
Acuratete: 1.00
Raport de clasificare:
precision recall f1-score support
setosa 1.00 1.00 1.00 10
versicolor 1.00 1.00 1.00 9
virginica 1.00 1.00 1.00 11
accuracy 1.00 30
macro avg 1.00 1.00 1.00 30
weighted avg 1.00 1.00 1.00 30
7. Experimentarea cu Diferite Valori ale K
Să vedem cum se schimbă performanța modelului în funcție de diferite valori ale K.
# Testam diferite valori pentru K
k_values = range(1, 31)
accuracies = []
for k in k_values:
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
accuracy = knn.score(X_test, y_test)
accuracies.append(accuracy)
# Vizualizam rezultatele
plt.figure(figsize=(10, 6))
plt.plot(k_values, accuracies, 'bo-')
plt.xlabel('Valoarea lui K')
plt.ylabel('Acuratete')
plt.title('Acuratete vs. Valoarea lui K')
plt.grid(True)
plt.show()
8. Functie pentru Predictii Noi
Cream o functie care ne permite sa facem predictii pentru noi masuratori.
def predict_iris(sepal_length, sepal_width, petal_length, petal_width, k=3):
# Cream și antrenam modelul
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
# Facem predictia
prediction = knn.predict([[sepal_length, sepal_width, petal_length, petal_width]])
return iris.target_names[prediction[0]]
# Exemplu de utilizare
print("\nExemplu de predictie:")
print(predict_iris(5.1, 3.5, 1.4, 0.2))
Exemplu de predictie:
setosa
9. Concluzii si Sfaturi Practice
- KNN este un algoritm simplu dar puternic pentru clasificare
- Alegerea lui K este importanta: K prea mic poate duce la overfitting, K prea mare poate duce la underfitting
- Datele trebuie sa fie normalizate pentru rezultate optime
- KNN poate fi lent pentru seturi mari de date
Exercitiul 1
Incercati diferite valori pentru K și observati efectele
# Codul tau aici:
Exercitiul 2
Testati modelul cu propriile masuratori
# Codul tau aici:
Exercitiul 3
Incercati sa normalizati datele inainte de antrenare
# Codul tau aici:
Titanic
Acesta este un cod pentru concursul "Titanic - Machine Learning from Disaster" de pe Kaggle. Vom folosi KNN, ceea ce nu va produce cele mai bune rezultate pe platforma, scopul sau fiind unul educativ :)
Importam toate librariile necesare:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, classification_report
Citirea
train_df = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
O sa vizualizam putin datele ca sa vedem cu ce lucram.
Vizualizarea datelor este primul si unul dintre cei mai importanti pasi in abordarea unei probleme de ML.
train_df.head()
PassengerId Survived Pclass \
0 1 0 3
1 2 1 1
2 3 1 3
3 4 1 1
4 5 0 3
Name Sex Age SibSp \
0 Braund, Mr. Owen Harris male 22.0 1
1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1
2 Heikkinen, Miss. Laina female 26.0 0
3 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1
4 Allen, Mr. William Henry male 35.0 0
Parch Ticket Fare Cabin Embarked
0 0 A/5 21171 7.2500 NaN S
1 0 PC 17599 71.2833 C85 C
2 0 STON/O2. 3101282 7.9250 NaN S
3 0 113803 53.1000 C123 S
4 0 373450 8.0500 NaN S
train_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
train_df.describe()
PassengerId Survived Pclass Age SibSp \
count 891.000000 891.000000 891.000000 714.000000 891.000000
mean 446.000000 0.383838 2.308642 29.699118 0.523008
std 257.353842 0.486592 0.836071 14.526497 1.102743
min 1.000000 0.000000 1.000000 0.420000 0.000000
25% 223.500000 0.000000 2.000000 20.125000 0.000000
50% 446.000000 0.000000 3.000000 28.000000 0.000000
75% 668.500000 1.000000 3.000000 38.000000 1.000000
max 891.000000 1.000000 3.000000 80.000000 8.000000
Parch Fare
count 891.000000 891.000000
mean 0.381594 32.204208
std 0.806057 49.693429
min 0.000000 0.000000
25% 0.000000 7.910400
50% 0.000000 14.454200
75% 0.000000 31.000000
max 6.000000 512.329200
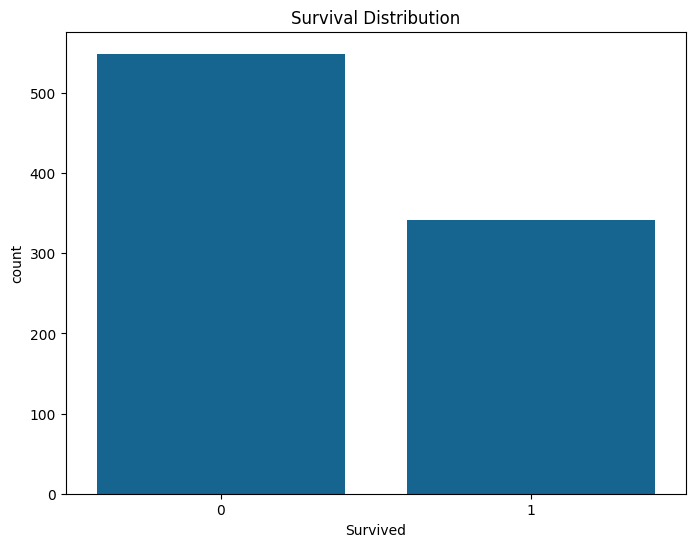
De multe ori valorile "brute" nu ne spun nimic asa ca vom plota datele pentru o vizualizare mai buna.
plt.figure(figsize=(8, 6))
sns.countplot(data=train_df, x='Survived')
plt.title('Survival Distribution')
plt.show()
sns.countplot(data=train_df, x='Pclass', hue='Survived')
plt.title('Survival by Passenger Class')
plt.show()
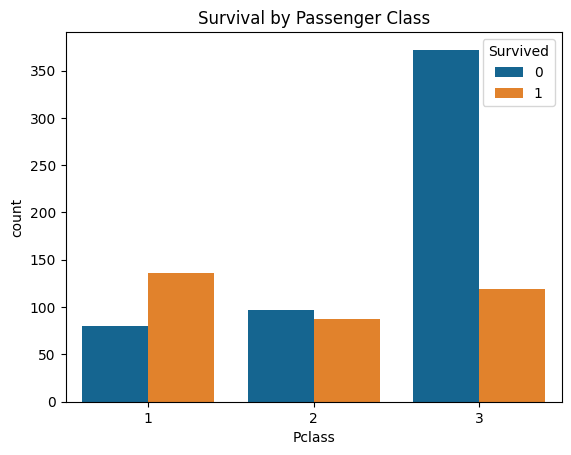
Putem schimba si culoarea prin adaugarea unui parametru de color:)
plt.figure(figsize=(10, 6))
sns.histplot(data=train_df, x='Age', bins=30, color="pink")
plt.title('Age Distribution')
plt.show()
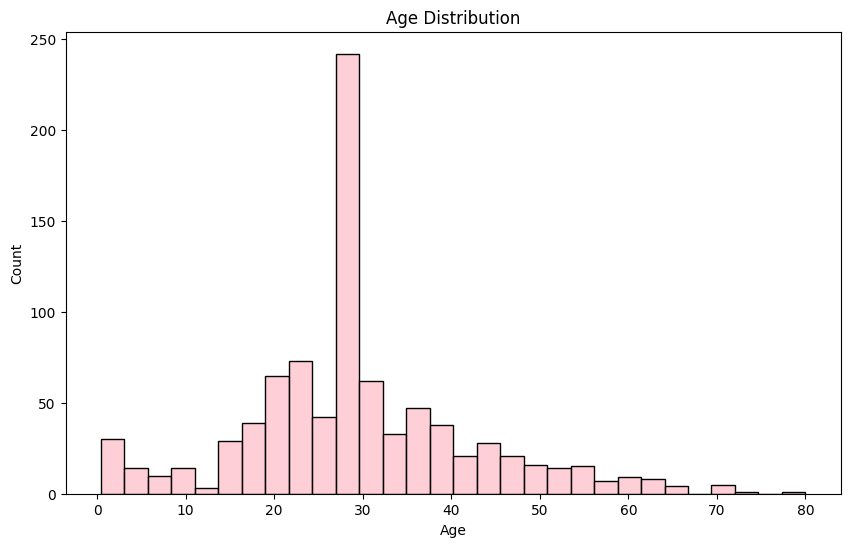
plt.figure(figsize=(8, 6))
sns.countplot(data=train_df, x='Sex', hue='Survived')
plt.title('Survival by Sex')
plt.show()
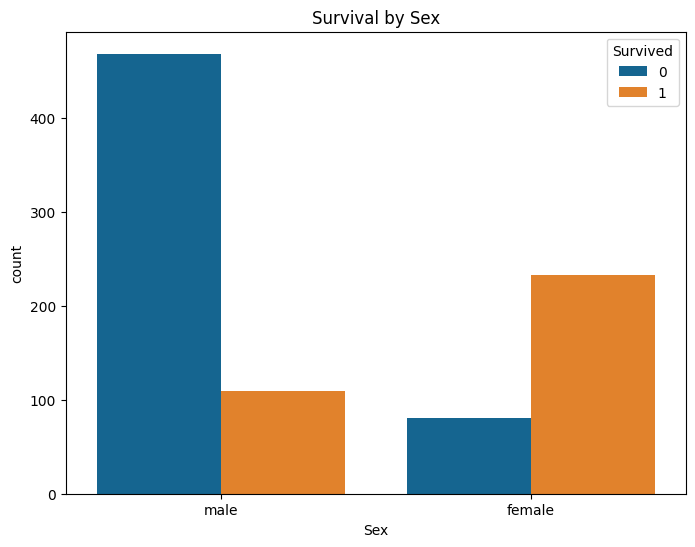
Ne asiguram sa nu avem valori nule
De asemenea, transformam valorile care nu sunt numerice in valori numerice pentru a fi intelese de modelul nostru.
In cazul nostru:
Female - > 0 Male - > 1
train_df['Age'] = train_df['Age'].fillna(train_df['Age'].median())
train_df['Embarked'] = train_df['Embarked'].fillna(train_df['Embarked'].mode()[0])
train_df['Fare'] = train_df['Fare'].fillna(train_df['Fare'].median())
train_df['Sex'] = train_df['Sex'].fillna(train_df['Sex'].mode()[0])
train_df['Sex'] = train_df['Sex'].map({'female': 0, 'male': 1})
features = ['Pclass', 'Sex', 'Age']
X = train_df[features]
y = train_df['Survived']
Ne impartim datele intr-un set de date de antrenament si unul de validare
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
k_values = range(1, 31)
train_scores = []
test_scores = []
for k in k_values:
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train_scaled, y_train)
train_scores.append(knn.score(X_train_scaled, y_train))
test_scores.append(knn.score(X_test_scaled, y_test))
plt.figure(figsize=(10, 6))
plt.plot(k_values, train_scores, label='Training Accuracy')
plt.plot(k_values, test_scores, label='Testing Accuracy')
plt.xlabel('k Value')
plt.ylabel('Accuracy')
plt.title('Accuracy vs k Value')
plt.legend()
plt.grid(True)
plt.show()
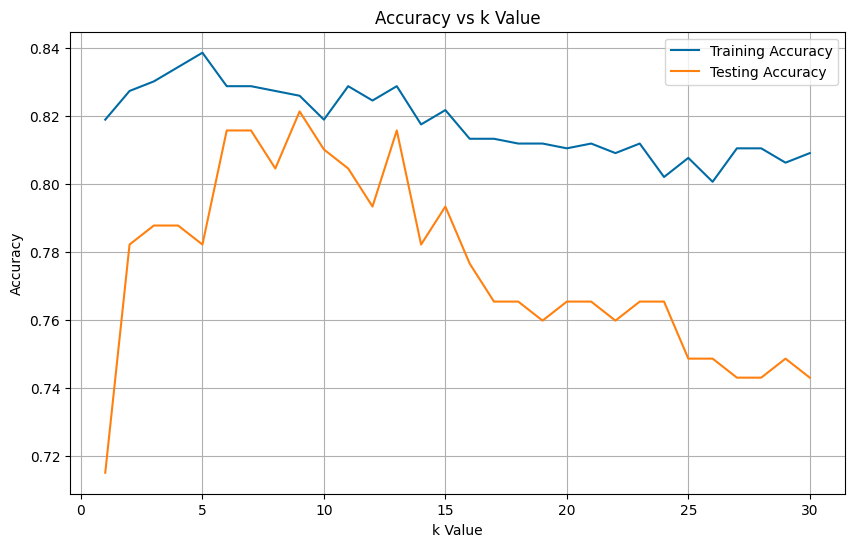
best_k = k_values[np.argmax(test_scores)]
print(f"\nBest k value: {best_k}")
Best k value: 9
final_model = KNeighborsClassifier(n_neighbors=best_k)
final_model.fit(X_train_scaled, y_train)
# Make predictions and evaluate
y_pred = final_model.predict(X_test_scaled)
print("\nAccuracy:", accuracy_score(y_test, y_pred))
print("\nClassification Report:")
print(classification_report(y_test, y_pred))
Accuracy: 0.8212290502793296
Classification Report:
precision recall f1-score support
0 0.81 0.91 0.86 105
1 0.85 0.69 0.76 74
accuracy 0.82 179
macro avg 0.83 0.80 0.81 179
weighted avg 0.82 0.82 0.82 179
passenger_ids = test_data['PassengerId']
test_data['Age'] = test_data['Age'].fillna(test_data['Age'].median())
test_data['Fare'] = test_data['Fare'].fillna(test_data['Fare'].median())
test_data['Sex'] = test_data['Sex'].fillna(test_data['Sex'].mode()[0])
test_data['Sex'] = test_data['Sex'].map({'female': 0, 'male': 1})
X_test_submit = test_data[features]
X_test_scaled_submit = scaler.transform(X_test_submit)
predictions = final_model.predict(X_test_scaled_submit)
submission = pd.DataFrame({
'PassengerId': passenger_ids,
'Survived': predictions
})
submission.to_csv('submission.csv', index=False)
print("Submission file shape:", submission.shape)
print("\nFirst few rows of submission file:")
print(submission.head())
Submission file shape: (418, 2)
First few rows of submission file:
PassengerId Survived
0 892 0
1 893 0
2 894 0
3 895 0
4 896 1
# Verify submission format
print("\nSubmission file info:")
print(submission.info())
print("\nValue counts in predictions:")
print(submission['Survived'].value_counts())
Submission file info:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 418 non-null int64
1 Survived 418 non-null int64
dtypes: int64(2)
memory usage: 6.7 KB
None
Value counts in predictions:
Survived
0 268
1 150
Name: count, dtype: int64
Incheiere
Sper ca v-a placut acest tutorial. Pe paginile noastre o sa gasiti in continuare informatii despre viitoare cursuri, competiti si evenimente