1. Ce sunt imaginile de fapt?
Autor: Luca Nicolae & Rares Stanciu, AIIS x Nitro AI Workshops 2025
Slide-uri: CV Slides
Pentru inceput ar trebui sa importam biblioteca Pillow sau PIL(Python Imaging Library). Aceasta ofera cea mai comoda metoda de a folosi imagini in Python. Pentru a urma in continuare tutorialul trebuie sa descarcati imaginea 'imagine.jpg' de pe github.
from PIL import Image
# Pentru a deschide in Python o imagine folosind PIL se foloseste functia open()
imagine = Image.open('imagine.jpg') # Ca parametru se va pune drumul catre imaginea pe care dorim sa o deschidem
Acum ca avem imaginea in cod, haideti sa vedem cum o putem afisa. Mai intai trebuie sa importam plt, biblioteca folosita de noi pentru vizualizarea datelor. Pentru a o afisa apoi, trebuie sa folosim functia imshow().
import matplotlib.pyplot as plt
plt.imshow(imagine)
<matplotlib.image.AxesImage at 0x7e6babd0e9d0>

# Acum ca stim cum sa afisam o imagine, este momentul sa aflam cate ceva despre structura ei
# Cum va arata daca incercam sa o printam?
print(imagine)
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=640x427 at 0x7E6BC01D1AD0>
# Nu pare foarte folositor... Ei bine, aici intervine numpy, care poate converti o astfel de imagine intr-un array astfel:
import numpy as np
imagine_array = np.array(imagine)
print(imagine_array.shape) # inaltime, latime, canale
(427, 640, 3)
# Interesant! Imaginea acum are forma unui array tridimensional de pixeli, unde prima dimensiune reprezinta inaltimea imaginii,
# cea de a doua reprezinta latimea ei si ultima reprezinta canalele colore.
# In cazul nostru avem 3 canale colore, faimoasele RGB(Red, Green, Blue)
print(imagine_array[0, :5]) # Asa arata primii 5 pixeli din imagine
[[65 77 41]
[60 74 38]
[58 73 40]
[55 75 40]
[51 72 39]]
# Stiind cum arata o imagine obisnuita RGB, este important sa intelegem si alte doua forme ale imaginilor dest intalnite: BGR si grayscale
# Imaginile in formatul BGR inverseaza ordinea canalelor. Acestea sunt folosite de unele modele de machine learning
# Un mod de a obtine imaginea in format BGR este urmatorul:
imagine_bgr_array = imagine_array[:, :, ::-1] # ':, :' -> selectam tot de pe randuri si coloane si '::-1' -> inversam ordinea canalelor
print(imagine_bgr_array[0, :5]) # Observam ca s-a inversat doar ordinea canalelor fiecarui pixel
[[41 77 65]
[38 74 60]
[40 73 58]
[40 75 55]
[39 72 51]]
<matplotlib.image.AxesImage at 0x7e6b9777fa10>

plt.imshow(imagine_bgr_array) # Daca afisam imaginea vom observa un fenomen interesant
<matplotlib.image.AxesImage at 0x7e6b978da2d0>

Cum plt.imshow() se asteapta sa gaseasca o imagine de tip RGB, culorile sunt putin dubioase :)
# Nu in ultimul rand, imaginile grayscale sunt folosite foarte des, deoarece ele pastreaza luminozitatea fiecarui pixel.
# Astfel, relatiile dintre pixeli, precum ar fi muchiile formate, inca se pot observa.
# Asa putem reduce de 3 ori dimensiunea unei imagini, intrucat ramane o singura valoare
# Putem converti imaginea noastra in grayscale astfel:
imagine_alb_negru = imagine.convert("L")
plt.imshow(imagine_alb_negru, cmap="gray") # ATENTIE! Pentru o afisare corecta a unei imagini grayscale, trebuie ca cmap="gray"
<matplotlib.image.AxesImage at 0x7e6b97712a90>

# Acum sa vedem cum arata array-ul specific acestei imagini
imagine_an_array = np.array(imagine_alb_negru)
print(imagine_an_array.shape) # Acum avem doar doua dimensiuni, pentru ca fiecare pixel tine doar o valoare, luminozitatea
print(imagine_an_array[0, :5])
(427, 640)
[69 66 65 65 62]
Curs Augmentare si Clasificare
Autor: Luca Nicolae, AIIS x Nitro AI Workshops 2025
Slide-uri: CV Slides
Content curs
- Intro computer vision -- prezentare
- Exemple de transformari in pytorch
- Prelucrarea unui dataset
- Antrenarea unui model
- Evaluarea performantei modelului antrenat
Tipuri de transformari
Libraria transforms din pytorch dispune de o serie larga de transformari pe imagini. Aceastea pot sa fie:
- Transformari de conversie intre formate
- Transformari de culoare. Modifica valorile pixelilor.
- Transformari geometrice. Modifica orientarea sau forma imaginii noastre.
- Trasnformari ce combin serii de imagini.
Importam librariile pe care le vom folosi
import torch
import torchvision.transforms.v2 as transforms
from torchvision.utils import make_grid
import cv2
import numpy as np
import urllib.request
import matplotlib.pyplot as plt
from PIL import Image
Descarcam o imagine de pe net
import numpy as np
import cv2
url ="https://renewcosolar.com.au/wp-content/uploads/2023/11/windmill-1024x682.jpg"
with urllib.request.urlopen(url) as url_response:
img_array = np.array(bytearray(url_response.read()),dtype=np.uint8)
img = cv2.imdecode(img_array,-1)
plt.imshow(cv2.cvtColor(img,cv2.COLOR_BGR2RGB))
plt.show()

Conversii intre formate
In python avem o serie de mai multe librarii care suporta imagini:
- Pillow
- Opencv
- Torchvision din Pytorch
Intre aceste librarii se pot face usor conversii a imaginilor, in functie de suportul celorlalte librarii cu care lucram sau de a functionalitatii de care avem nevoie. In exemplul de mai sus pentru a decoda imaginea descarcata ne-am folosit de opencv.
# Imaginea din OpenCV ( Lucreaza cu valorile de R si B inversate, formatul valorilor pixelilor fiind BGR )
plt.imshow(img)
plt.show()
# Facem conversie in Pillow ( Revenim cu formatul pixelilor in RGB)
pillow_img = Image.fromarray(cv2.cvtColor(img,cv2.COLOR_BGR2RGB))
plt.imshow(pillow_img)
plt.show()
# Pentru a lucra cu transformarile, si modele din pytorch trebuie sa schimbat imaginea in formatul de tensor
tensor_img = transforms.ToTensor()(pillow_img)
print(tensor_img.shape)
# Conversie inapoi in format pillow
pillow_img = transforms.ToPILImage()(tensor_img)
plt.imshow(pillow_img)
plt.show()
#Conversie din pillow in opencv
cv_image = cv2.cvtColor(np.array(pillow_img),cv2.COLOR_RGB2BGR)
plt.imshow(cv_image)
plt.show()


/usr/local/lib/python3.11/dist-packages/torchvision/transforms/v2/_deprecated.py:42: UserWarning: The transform `ToTensor()` is deprecated and will be removed in a future release. Instead, please use `v2.Compose([v2.ToImage(), v2.ToDtype(torch.float32, scale=True)])`.Output is equivalent up to float precision.
warnings.warn(
torch.Size([3, 682, 1024])


In continuare o sa lucram cu formatul de tensor
Transformari de culoare
# Imaginea originala
plt.imshow(transforms.ToPILImage()(tensor_img))
plt.show()

# Color Jitter
variations = []
for i in range(6):
variations.append(transforms.ColorJitter(brightness = 0.3, contrast = 0.15, saturation = 0.1, hue = 0.1)(tensor_img))
grid = make_grid(variations, nrow = 3, padding = 4)
plt.figure(figsize = (10,5) )
plt.imshow(grid.transpose(0,1).transpose(1,2).numpy())
plt.show()
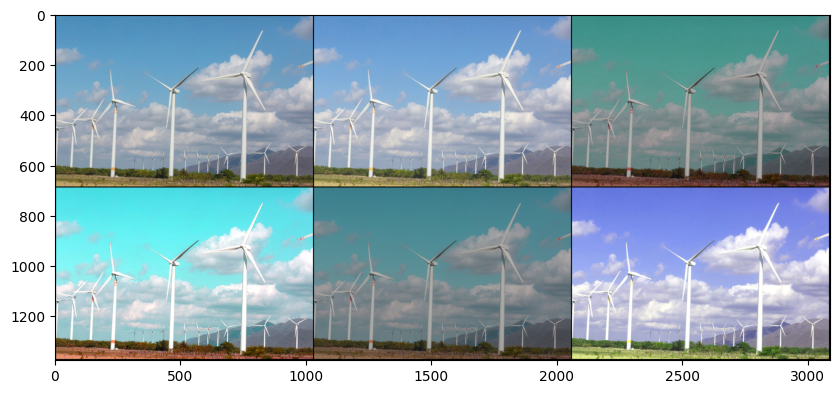
# Grayscale
img = transforms.Grayscale()(tensor_img)
plt.imshow(transforms.ToPILImage()(img),cmap='gray')
plt.show()

# GaussianBlur
img = transforms.GaussianBlur(kernel_size=(11,11),sigma=(0.2,5))(tensor_img)
plt.imshow(transforms.ToPILImage()(img))
plt.show()

# GaussianNoise
img = transforms.GaussianNoise(mean=0,sigma=min(0.2,np.random.random()))(tensor_img)
plt.imshow(transforms.ToPILImage()(img))
plt.show()

# RandomSolarize
img = transforms.RandomSolarize(threshold=np.random.randint(215,240)/255,p=1)(tensor_img)
plt.imshow(transforms.ToPILImage()(img))
plt.show()

Transformari geometrice
# Resize
img = transforms.Resize(size=(900,900))(tensor_img)
plt.imshow(transforms.ToPILImage()(img))
plt.show()
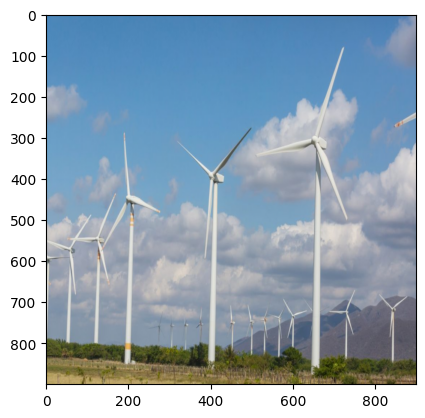
# Crop
img = transforms.RandomCrop(size=(500,500))(tensor_img)
plt.imshow(transforms.ToPILImage()(img))
plt.show()
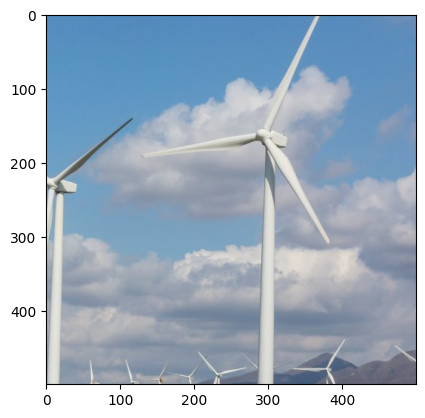
# RandomRotation
img = transforms.RandomRotation(degrees=(-25,25))(tensor_img)
plt.imshow(transforms.ToPILImage()(img))
plt.show()

# Affine
img = transforms.RandomAffine(degrees=(-25,25), translate=(0.2,0.2))(tensor_img)
plt.imshow(transforms.ToPILImage()(img))
plt.show()

# ElasticTransform
img = transforms.ElasticTransform(alpha = np.random.randint(50,150), sigma=5)(tensor_img)
plt.imshow(transforms.ToPILImage()(img))
plt.show()

# HorizontalFlip
img = transforms.RandomHorizontalFlip(p=0.5)(tensor_img)
plt.imshow(transforms.ToPILImage()(img))
plt.show()

# VerticalFlip
img = transforms.RandomVerticalFlip(p=1)(tensor_img)
plt.imshow(transforms.ToPILImage()(img))
plt.show()

Transformari pe serii
urls = ['https://renewcosolar.com.au/wp-content/uploads/2023/11/windmill-1024x682.jpg',
'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRig9hn_RcvkEkIBSxIowkUS7fvObYiYm8qVw&s',
'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQEDbjf1725m8mcTJA1wfX2jb3aEg1tJaxg4g&s'
]
images = []
for url in urls:
with urllib.request.urlopen(url) as url_response:
img_array = np.array(bytearray(url_response.read()),dtype=np.uint8)
img =cv2.cvtColor(cv2.imdecode(img_array,-1),cv2.COLOR_BGR2RGB)
images.append(transforms.Resize((800,1000))(transforms.ToTensor()(img)))
grid = make_grid(images, nrow = 3, padding = 4)
plt.figure(figsize = (10,5) )
plt.imshow(grid.transpose(0,1).transpose(1,2).numpy())
plt.show()
/usr/local/lib/python3.11/dist-packages/torchvision/transforms/v2/_deprecated.py:42: UserWarning: The transform `ToTensor()` is deprecated and will be removed in a future release. Instead, please use `v2.Compose([v2.ToImage(), v2.ToDtype(torch.float32, scale=True)])`.Output is equivalent up to float precision.
warnings.warn(

# CutMix
labels = torch.zeros(len(images)).unsqueeze(dim=1)
batch_images = torch.stack(images)
res = transforms.CutMix(num_classes=1, alpha = 1.0)(batch_images,labels)
grid = make_grid(res[0], nrow = 3, padding = 4)
plt.figure(figsize = (10,5) )
plt.imshow(grid.transpose(0,1).transpose(1,2).numpy())
plt.show()

# MixUp
labels = torch.zeros(len(images)).unsqueeze(dim=1)
batch_images = torch.stack(images)
res = transforms.MixUp(num_classes=1, alpha = 1.0)(batch_images,labels)
grid = make_grid(res[0], nrow = 3, padding = 4)
plt.figure(figsize = (10,5) )
plt.imshow(grid.transpose(0,1).transpose(1,2).numpy())
plt.show()
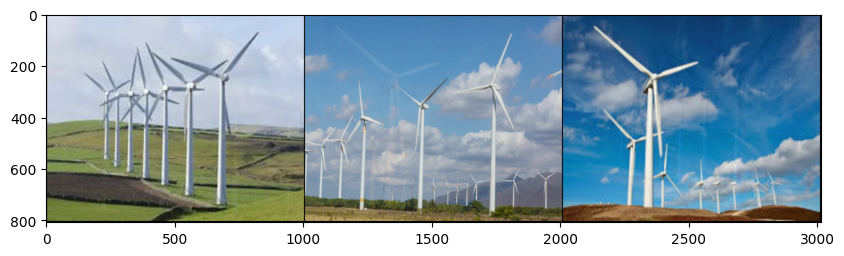
Augmentarea unui dataset
Vom folosi dataset-ul https://www.kaggle.com/datasets/kylegraupe/wind-turbine-image-dataset-for-computer-vision
!pip install kaggle==1.5.12
!mkdir -p ~/.kaggle
!cp kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
!kaggle datasets download kylegraupe/wind-turbine-image-dataset-for-computer-vision
Downloading wind-turbine-image-dataset-for-computer-vision.zip to /content 100% 615M/617M [00:33<00:00, 20.8MB/s] 100% 617M/617M [00:33<00:00, 19.2MB/s]
!unzip /content/wind-turbine-image-dataset-for-computer-vision.zip
Vom folosi doar imagini cu windmills si cabletower
# Filtram pozele noastre
import os
import glob
train_paths = []
test_paths = []
windmills_cnt =0
cabletower_cnt = 0
files = glob.glob(os.path.join('/content/train/images','*'))
for path in files:
if 'windmill' in path and windmills_cnt < 60:
train_paths.append([path,0])
windmills_cnt += 1
if 'cabletower' in path and cabletower_cnt < 60:
train_paths.append([path,1])
cabletower_cnt += 1
if windmills_cnt == 60 and cabletower_cnt == 60:
break
windmills_cnt =0
cabletower_cnt = 0
files = glob.glob(os.path.join('/content/test/images','*'))
for path in files:
if 'windmill' in path and windmills_cnt < 10:
test_paths.append([path,0])
windmills_cnt += 1
if 'cabletower' in path and cabletower_cnt < 10:
test_paths.append([path,1])
cabletower_cnt += 1
if windmills_cnt == 10 and cabletower_cnt == 10:
break
# Putem afisa cateva din imaginile noastre
images = []
for data in train_paths[:20]:
images.append(transforms.ToTensor()(Image.open(data[0]).resize((640,480))))
grid = make_grid(images, nrow = 3, padding = 4)
plt.figure(figsize = (10,5) )
plt.imshow(grid.transpose(0,1).transpose(1,2).numpy())
plt.show()
# Ne declaram dataset-ul
import torch.utils.data as tdata
device = 'cuda'
class Dataset(tdata.Dataset):
def __init__(self,data):
self.images = []
self.labels = []
for d in data:
self.images.append(transforms.ToTensor()(Image.open(d[0]).resize((1920,1080))))
self.labels.append(torch.tensor(1000 + d[1]))
def __getitem__(self,idx):
return self.images[idx].to(device), self.labels[idx].to(device)
def __len__(self):
return len(self.images)
train_dataset = Dataset(train_paths)
test_dataset = Dataset(test_paths)
plt.imshow(transforms.ToPILImage()(train_dataset[0][0]))
plt.plot()
[]
# Declaram functia de collate si Dataloader-ul
batch_size = 5
def collate_fn(examples):
images = []
labels = []
for id in range(batch_size):
images.append(examples[id][0].to(device))
labels.append(examples[id][1].to(device))
custom_transforms = transforms.Compose([
transforms.RandomApply([transforms.ColorJitter(brightness = 0.3, contrast = 0.15, saturation = 0.1, hue = 0.1)],p=0.3),
transforms.RandomApply([transforms.GaussianBlur(kernel_size=(11,11),sigma=(0.2,5))],p=0.3),
transforms.RandomApply([transforms.GaussianNoise(mean=0,sigma=min(0.2,np.random.random()))],p=0.3),
transforms.RandomApply([transforms.RandomSolarize(threshold=np.random.randint(215,240)/255,p=1)],p=0.3),
transforms.RandomApply([transforms.RandomAffine(degrees=(-25,25), translate=(0.2,0.2))],p=0.3),
transforms.RandomVerticalFlip(p=0.3)
])
for id in range(batch_size):
images.append(custom_transforms(examples[id][0]).to(device))
labels.append(examples[id][1].to(device))
return images, labels
train_dataloader = tdata.DataLoader(
train_dataset,
collate_fn=collate_fn,
batch_size=batch_size
)
Antrenarea unui model
In demo-ul nostru o s antrenam si evaluam un model de clasificare
# Incarcam modelul preantrenat
from torchvision.io import decode_image
from torchvision.models import resnet50, ResNet50_Weights
weights = ResNet50_Weights.DEFAULT
model = resnet50(weights)
model.to(device)
preprocess = weights.transforms()
/usr/local/lib/python3.11/dist-packages/torchvision/models/_utils.py:135: UserWarning: Using 'weights' as positional parameter(s) is deprecated since 0.13 and may be removed in the future. Please use keyword parameter(s) instead.
warnings.warn(
# Testam modelul de baza pe o imagine
def predict(tensor_img):
prediction = model(preprocess(tensor_img).unsqueeze(0)).squeeze(0).softmax(0)
class_id = prediction.argmax().item()
score = prediction[class_id].item()
category_name = weights.meta['categories'][class_id]
print(f'{category_name}: {100 * score:.1f}%')
predict(train_dataset[0][0])
tripod: 0.3%
# Modelul nu cunoaste clasele noastre
'windmill' in weights.meta['categories'] or 'cabletower' in weights.meta['categories']
False
Pentru a antrena pe clasa noastra va trebui sa modificam ultimul layer din model
output_weights = model.fc.weight.data
output_bias = model.fc.bias.data
new_layer = torch.nn.Linear(model.fc.in_features, output_weights.shape[0] + 2)
new_layer.weight.data[:output_weights.shape[0],:] = output_weights
new_layer.bias.data[:output_bias.shape[0]] = output_bias
model.fc = new_layer
weights.meta['categories'].append('windmill')
weights.meta['categories'].append('cabletower')
model.to(device)
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=1002, bias=True)
)
# Declaram criterion-ul si optimizer-ul
import torch.optim as optim
import torch.nn as nn
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr = 0.00001)
# Antrenam modelul
from tqdm import tqdm
epochs = []
epoch_loss = []
for epoch in tqdm(range(15)):
tloss = 0
model.train()
for data in train_dataloader:
images, labels = data
preprocessed_images = [ preprocess(image).to(device) for image in images]
preprocessed_batch = torch.stack(preprocessed_images,dim=0)
outputs = model(preprocessed_batch)
loss = criterion(outputs,torch.stack(labels))
loss.backward()
optimizer.step()
tloss += loss.item()
epochs.append(epoch)
epoch_loss.append(tloss)
100%|██████████| 15/15 [00:30<00:00, 2.06s/it]
# Verificam loss-ul
plt.plot(epochs,epoch_loss)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
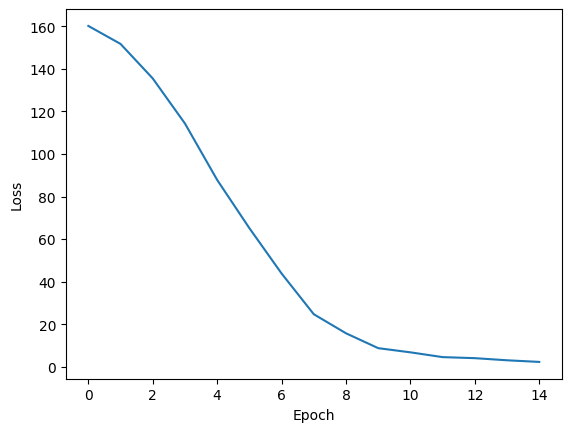
Testam modelul daca a invatat
model.eval()
for data in test_dataset:
print('Correct class:', weights.meta['categories'][data[1].item()])
predict(data[0])
print()
Correct class: windmill
windmill: 99.9%
Correct class: windmill
windmill: 99.6%
Correct class: windmill
windmill: 94.6%
Correct class: windmill
windmill: 93.1%
Correct class: windmill
windmill: 99.5%
Correct class: windmill
windmill: 95.3%
Correct class: windmill
windmill: 94.6%
Correct class: windmill
windmill: 99.3%
Correct class: windmill
windmill: 99.8%
Correct class: windmill
windmill: 99.7%
Correct class: cabletower
cabletower: 85.9%
Correct class: cabletower
cabletower: 97.2%
Correct class: cabletower
cabletower: 89.5%
Correct class: cabletower
cabletower: 97.5%
Incheiere
Sper ca v-a placut acest tutorial. Pe paginile noastre o sa gasiti in continuare informatii despre viitoare cursuri, competiti si evenimente