PCA (Principal Componant Analisys)
Autor: Morariu Tudor, AIIS
Intro in PCA
Ce este PCA?
PCA este un algoritm de descompunere a datelor in dimensiuni mai mici. Este un algoritm nesupervisat, care functioneaza pe un principiu matematic, fara a folosi functii de optimizare precum Gradient Descent.
In practica se foloseste pentru vizualizarea datelor care sunt compuse din mai mult de 2 featureuri.
Cum funcționează PCA?
Scopul PCA.
In input, algoritmul primeste un set de date X \in \mathbb{R}^{n \times p} si output-ul trebuie sa fie un set de date $ D \in \mathbb{R}^{n \times k} $.
Setul de date obtinut, D, trebuie sa pastreze reprezentarea datelor cat mai apropiata de cea originala din X.
Setul de date.
Presupunem că avem un set de date:
Se presupune ca setul de date, X, este standadizat. In acest mod toate datele au aceasi importanta.
Unde:
- n = numărul de linii
- p = numărul de feature-uri
- X = [x_{ij}] , cu i = 1..n , j = 1..p
Matricea de covariatie.
Primul pas din algoritmul de PCA este calcularea matricei de covariatie.
Corelația dintre două feature-uri X_i și X_j este:
unde:
Is esenta, covariatia spune cat de proportionale sunt cele doua valori. Cu cat este mai apropiata de 1, cu atat cele doua feature-uri sunt direct proportionala si invers proporitionale cat se apropie de -1.
Matricea de corelație R este o matrice pătratică:
definită astfel:
unde:
- R_{ii} = 1 (corelația unei variabile cu ea însăși)
- R_{ij} \in [-1, 1]
- R este simetrică: R_{ij} = R_{ji}
Forma generală:
Valorile Proprii ale unei matrici.
Daca consideram matricea R ca o transformare in spatiu, vectori proprii sunt versorii care nu isi schimba orientarea in spatiu, iar valorile proprii sunt factorul cu care se modifica vetorii acestia.
Din caculul acestor valori vor rezulta p valori proprii.
Se noteaza cu \lambda_i, unde \lambda_i este valoarea proprie pentru a i-a dimensiune.
Valorile proprii se obțin rezolvând ecuația caracteristică:
Datele Reduse.
În final, datele reduse se obțin prin proiecția datelor standardizate pe subspațiul generat de vectorii proprii corespunzători celor mai mari $ k $ valori proprii.
Fie: * V_k \in \mathbb{R}^{p \times k} matricea formată din primii k vectori proprii, ordonați descrescător după valorile proprii * X \in \mathbb{R}^{n \times p} setul de date standardizat
Atunci datele reduse D sunt:
unde:
- D \in \mathbb{R}^{n \times k}
- fiecare linie din D reprezintă un exemplu din setul de date, exprimat în noul spațiu de dimensiune k
Interpretare intuitivă:
- Vectorii proprii definesc direcțiile cu cea mai mare variație din date
- Proiecția pe acești vectori păstrează maximum de informație posibilă pentru un număr redus de dimensiuni
- Valorile proprii indică câtă variație explică fiecare componentă principală
De obicei, k < p , iar suma primelor k valori proprii explică un procent mare din variația totală a datelor.
Implementare
import numpy as np
# 1. Standardizarea datelor
date_standardizate = (date - date.mean(axis=0)) / date.std(axis=0)
# 2. Calcularea matricei de covarianță
matrice_covarianta = np.cov(date_standardizate, rowvar=False, ddof=1)
# 3. Calcularea valorilor proprii și a vectorilor proprii
valori_proprii, vectori_proprii = np.linalg.eig(matrice_covarianta)
# 4. Sortarea valorilor proprii în ordine descrescătoare
ordine_importanta = np.argsort(valori_proprii)[::-1]
valori_proprii_sortate = valori_proprii[ordine_importanta]
vectori_proprii_sortati = vectori_proprii[:, ordine_importanta]
# 5. Reducerea dimensionalității
k = 2 # numărul de componente principale
date_reduse = np.matmul(date_standardizate, vectori_proprii_sortati[:, :k])
De ce PCA?
In practica PCA este utilizat pentru vizionarea datelor. Un exemplu este plottarea datelor din setul MNIST pe axe 2D.
Este o metoda rapida pentru a compresa mai multe featureuri in dimensiui mai mici, patrand orientarea relativa intre datele originale.
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
D = PCA(2).fit_transform(X)
plt.scatter(D[:, 0], D[:, 1], c=y)
In codul acesta calculam punctele 2D din pixeli dati de MNIST. Fiecare cifra C \in \mathbb{R}^{28 \times 28} . Toate cifrele sunt puse intr-o matrice X \in \mathbb{R}^{n \times 784}
D \in \mathbb{R}^{n \times 2} , astfel se pot plota frumos.
y este un vector cu clasa fiecarui exemplu.
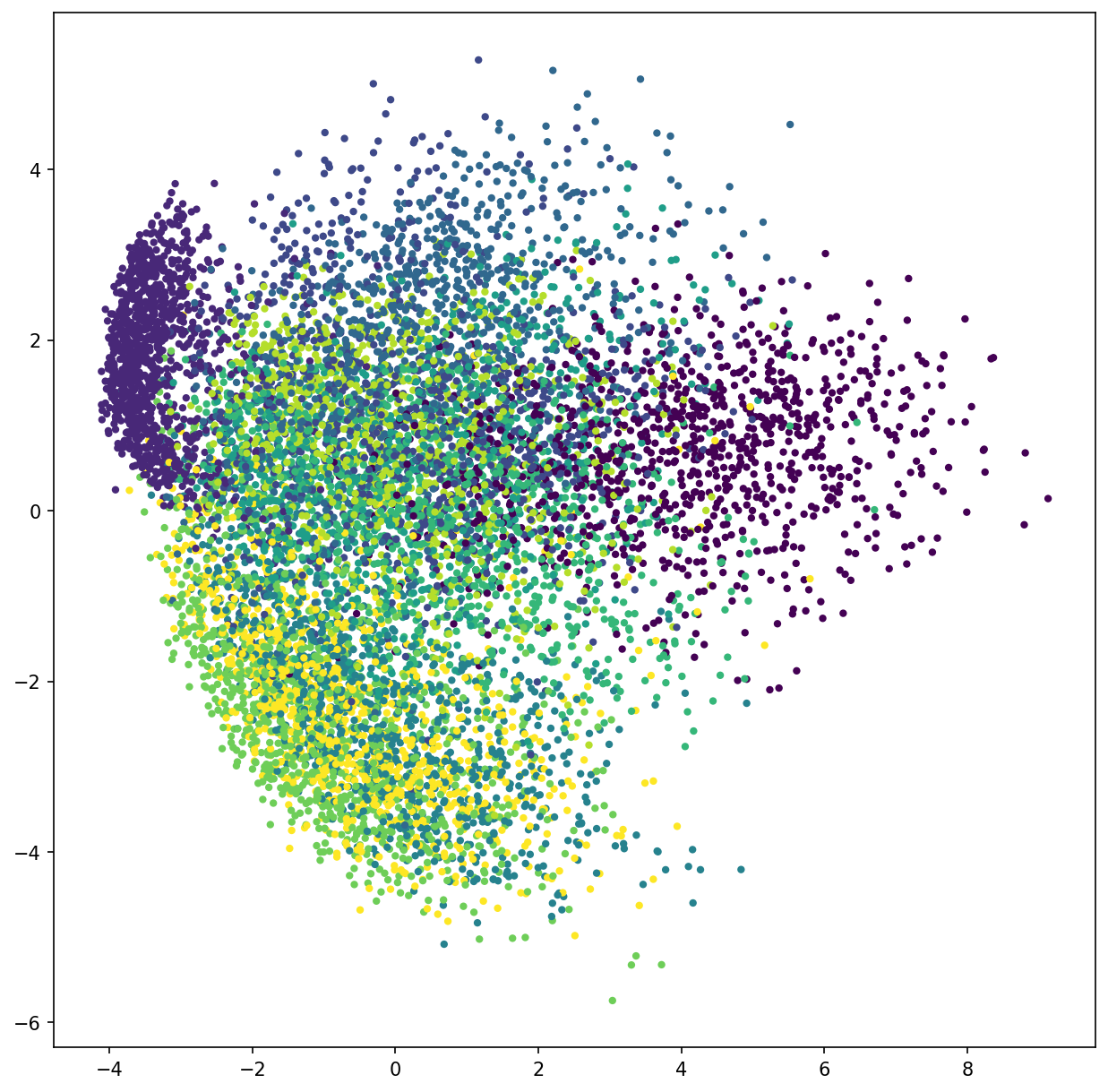
Aici putem vedea o separare relativ clara intre clase.
Exemplu complet
Vom exemplifica folosirea algoritmului PCA pe setul de date Iris. Setul de date Iris conține 150 de observații și 4 feature-uri (lungimea și lățimea sepalei și petalei), grupate în 3 clase.
Pașii sunt:
- standardizarea datelor;
- aplicarea PCA;
- proiecția în 2D pentru vizualizare.
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
X, y = load_iris(return_X_y=True)
X_std = StandardScaler().fit_transform(X)
X_pca = PCA(n_components=2).fit_transform(X_std)
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y)
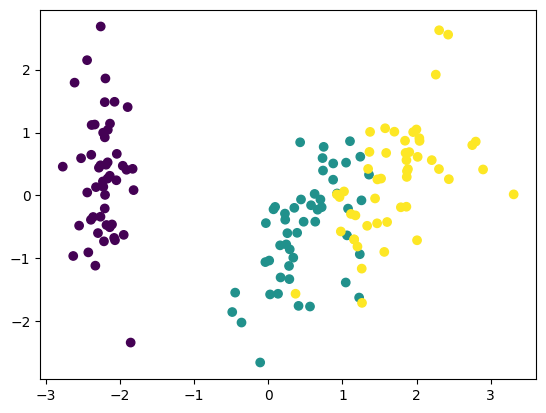
Concluzii si Sfaturi Practice
- Standardizarea este esențială înainte de PCA.
- PCA este o metodă liniară și nu surprinde relații neliniare.
- Reducerea dimensionalității poate îmbunătăți performanța și interpretabilitatea modelelor.