Regresie Liniară
Autor: Miruna Zăvelcă, Carla Crivoi
Rezolvă în Colab: Regresie Liniară
Scop
Scopul regresiei liniare este să găsească o linie dreaptă care minimizează eroarea dintre punctele de date observate și valorile prezise.
Presupunerile regresiei liniare
-
Liniaritate: Relația dintre features (X) și predicții (Y) este liniară.
-
Independența erorilor: Erorile din predicții nu trebuie să se influențeze între ele.
-
Varianță constantă (Homoscedasticitate): Erorile trebuie să aibă o răspândire constantă pentru toate valorile intrării. Dacă răspândirea variază (se lărgește sau se îngustează), fenomenul se numește heteroscedasticitate și afectează modelul.
-
Normalitatea erorilor: Erorile trebuie să urmeze o distribuție normală.
-
Fără multicoliniaritate (pentru regresie multiplă): Variabilele de intrare nu trebuie să fie puternic corelate între ele.
Tipuri
- Regresie liniară simplă
Folosită când dorim să prezicem o valoare țintă folosind o singură caracteristică de intrare. Presupune o relație liniară între cele două.
y = θ_0 + θ_1 * x
- Regresie liniară multiplă
y = θ_0 + θ_1 * x_1 + θ_2 * x_2 + ... + θ_n * x_n
Exercițiul 1
Calculează linia de regresie (funcția acesteia) pentru datele de mai jos:
| x | y |
|---|---|
| 1 | 2 |
| 2 | 3 |
| 3 | 5 |
| 4 | 4 |
Pasul 1. Calculează media
Pasul 2. Calculează panta \beta_1
Pasul 3. Calculează \beta_0
Linia de regresie finală:
Californa Housing
Pentru a exemplifica mai ușor metricile pe regresie vom folosi setul de date preinstalat în Colab, california_housing, folosind coloana median_house_value drept label:
import pandas as pd
df = pd.read_csv('sample_data/california_housing_train.csv')
df.head()
y_train = df['median_house_value'].to_numpy()
df = df.drop(columns=['median_house_value'])
X_train = df.to_numpy()
df = pd.read_csv('sample_data/california_housing_test.csv')
y_test = df['median_house_value'].to_numpy()
df = df.drop(columns=['median_house_value'])
X_test = df.to_numpy()
Exercițiul 2
Stabiliți niște statistici descriptive generale pentru setul de date. Exemplu: - Media pe fiecare coloana - Mediana pe fiecare - Deviatia standard
Exercițiul 3
Plotați venitul median vs valoarea locuinței (MedInc vs MedHouseVal)
Exercițiul 4
Calculați numărul de camere per vârstă a clădirii (HouseAge), numărul de dormitoare per cameră, populație per gospodărie
Exercițiul 5
Ne uităm la coloanele Latitude și Longitude pentru a vedea cum se distribuie prețurile caselor în California.
Exercițiul 6
Plotați HouseAge în categorii (ex: 0-10, 11-20, etc.) + media prețurilor în fiecare categorie
Antrenăm setul de date cu un LinearRegression simplu pentru a avea acces mai ușor la datele prezise.
from sklearn.linear_model import LinearRegression
clf = LinearRegression()
clf = clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
Putem pune rezultatele pe un grafic pentru a observa distanța între valorile prezise și cele corecte.
import seaborn as sns
data = pd.DataFrame({'expected': y_test, 'predicted': y_pred})
sns.regplot(x = 'expected', y = 'predicted', data=data, line_kws={"color": "orange"})
<Axes: xlabel='expected', ylabel='predicted'>
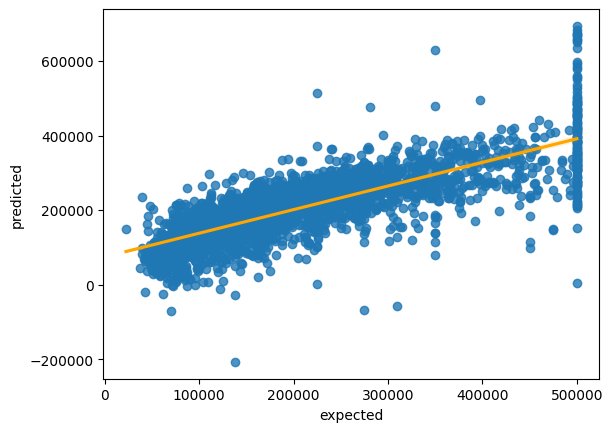
Exercițiul 7
Linia din desenul de mai sus reprezintă funcția pe care ne așteptam să avem labelurile, iar punctele reprezintă poziția corectă a acestora. Ce vă sugerează acest grafic?
Soluția aici
Metrici
Penalizare (Penalty)
Pentru a măsura dimensiunea unui vector în matematică folosim norma (distanța de la origine la punctul x):
L^p = ||x||_p = (\sum\limits_i |x_i|^p )^{\frac{1}{p}}
pentru p \in R, p \geq 1
În general, în Machine Learning se folosește una dintre următoarele norme pentru a îmbunătăți un algoritm:
-
L^0 = \sum\limits_i 1
-
L^1 = \sum\limits_i |x_i|
-
L^2 = \sqrt{\sum\limits_i |x_i|^2}
-
L^\infty = \max\limits_i |x_i|
L^0 - Câte elemente diferite de 0 există?
Tehnic nu este o normă, întrucât nu respectă toate proprietățile matematice ale unei norme. De multe ori în practică este înlocuită cu L^1.
L^1 - Suma elementelor
Diferențiază între elementele care sunt exact 0 și elemente foarte mici, dar nonzero. Este utilizată atunci când diferența între elementele nule și cele nenule este foarte importantă.
L^2 - Norma Euclidiană
Calculează distanța euclidiană de la origine la punctul x. Norma utilizată cel mai des în ML. Diferențiază foarte prost între elemente apropiate de origine.
L^∞ - Norma Maximă
Valoare elementului cel mai depărtat de origine.
Mean Squared Error (MSE)
$ MSE = \frac{1}{N} * Σ_{(x, y) \in D} (y - prediction(x)) ^ {2}$
Unde:
-
D = setul de date
-
N = numărul de datapoints din D
-
x = setul de features pentru un datapoint
-
y = labelul aceluiasi datapoint
-
prediction(x) = funcția care prezice labelul pentru setul de features x
from sklearn.metrics import mean_squared_error
print("Model MSE on train: ", mean_squared_error(y_train, clf.predict(X_train)))
print("Model MSE on test: ", mean_squared_error(y_test, y_pred))
Model MSE on train: 4824523173.926901
Model MSE on test: 4867205486.928806
Underfitting, overfitting...
Indiferent ce model am folosi, outputul este o funcție care modelează mai bine, sau mai puțin bine, datele problemei. Dacă punem această funcție pe un grafic vom observa acest aspect destul de repede:
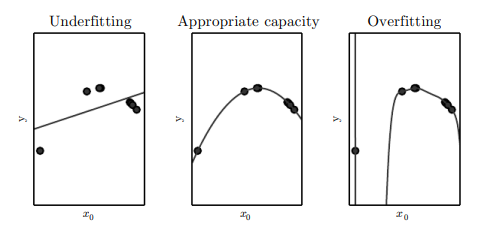
În primul exemplu funcția modelează o linie dreaptă, destul de îndepărtată de puncte, dar probabil cea mai bună variantă pe forma respectivă. În ultimul exemplu funcția trece prin toate punctele, dar forma nu este una naturală, așadar ne putem aștepta să nu generalizeze bine pe exemple noi. A doua funcție este simplă și clară. Am fi preferat o funcție de forma asta chiar dacă nu trecea neapărat prin toate punctele.
Briciul lui Occam (Occam's razor) -- "entitățile nu trebuie să fie multiplicate dincolo de necesar"
Adică între 2 teorii la fel de corecte, mereu o vom prefera pe cea mai simplă.
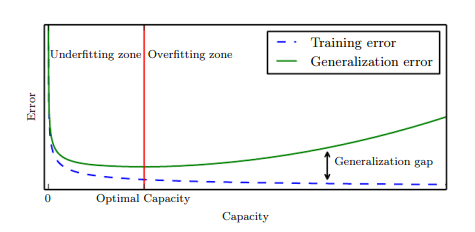
În exemplul de mai sus vedem cum mai multe date de antrenare nu ne asigură neapărat un rezultat mai bun. În funcție de problema pe care vrem să o rezolvăm capacitatea optimă a setului de date va fi diferită.
Sursă imagini: Deep Learning -- Book by Aaron Courville, Ian Goodfellow, and Yoshua Bengio