Arbori de Decizie
Autor: Miruna Zăvelcă, Carla Crivoi
Rezolvă în Colab: Arbori de Decizie
Arborii de decizie sunt utilizați atât pentru probleme de clasificare cât și pentru probleme de regresie. Algoritmul este tip greedy: la fiecare pas analizăm o arie de distribuție mixtă din datele noastre și o împărțim în 2 părți (de dimensiuni probabil diferite) astfel încât fiecare parte să aibă predominant date dintr-o clasă diferită.
Play Tennis – Dataset
| # | Outlook | Temperature | Humidity | Windy | Play Tennis |
|---|---|---|---|---|---|
| 0 | Rainy | Hot | High | False | No |
| 1 | Rainy | Hot | High | True | No |
| 2 | Overcast | Hot | High | False | Yes |
| 3 | Sunny | Mild | High | False | Yes |
| 4 | Sunny | Cool | Normal | False | Yes |
| 5 | Sunny | Cool | Normal | True | No |
| 6 | Overcast | Cool | Normal | True | Yes |
| 7 | Rainy | Mild | High | False | No |
| 8 | Rainy | Cool | Normal | False | Yes |
| 9 | Sunny | Mild | Normal | False | Yes |
| 10 | Rainy | Mild | Normal | True | Yes |
| 11 | Overcast | Mild | High | True | Yes |
| 12 | Overcast | Hot | Normal | False | Yes |
| 13 | Sunny | Mild | High | True | No |
Exercițiul 1
Calculează impuritatea Gini pentru coloanele Outlook și Temperature. În funcție de care feature ar trebui să împărțim tabelul prima dată?
Soluție aici
Exercițiul 2
Calculează entropia pentru coloanele Outlook și Temperature. În funcție de care feature ar trebui să împărțim tabelul prima dată?
Soluție aici
Definiții
Fie S setul de date de antrenare disponibile într-un nod dat.
- Probabilitatea clasei k:
$$ p_k(S) = \frac{1}{|S|} \sum_{i \in S} \mathbf{1}{y^{(i)}=k} $$
- Impuritatea Gini:
$$ G(S) = 1 - \sum_{k=1}^K p_k(S)^2 $$
- Entropie:
$$ H(S) = - \sum_{k=1}^K p_k(S) \log_2 p_k(S) $$
Algoritm
La fiecare pas algoritmul alege un feature x_j și un threshold t în funcție de care împarte setul de date S în S_l, pentru toți x_j \leq t, și S_r, pentru toți x_j > t
Împărțirea e aleasă astfel încât să maximizeze puritatea celor 2 părți pentru clasificare sau să minimizeze variația pentru regresie.
Clasificare
Când împărțim datapointurile din nodul S în S_l și S_r impuritatea o să scadă cu:
Alegem (j, t) astfel încât să maximizăm \Delta i.
Regula de predicție: \hat{y} = \arg \max_k p_k(S)
Exercițiul 3
Fie setul de date de mai jos:
| Student | Study Hours | Pass? |
|---|---|---|
| 1 | 2 | No |
| 2 | 4 | No |
| 3 | 6 | Yes |
| 4 | 7 | Yes |
| 5 | 8 | Yes |
Calculează impuritatea Gini în funcție de ultima coloană.
În funcție de ce valoare t a coloanei Study hours vom împărți datasetul astfel încât să maximizăm impuritatea?
Rezolvare aici
Regresie
Pentru nodul S, prezicem media:
Și eroarea (varianța în nod):
Când împărțim în S_l și S_r varianța o să se modifice cu:
Alegem (j, t) astfel încât să maximizăm \Delta R(j, t).
Regula de predicție: \hat{y} = \frac{1}{|S|} \sum_{i \in S} y^{(i)}
Exercițiul 4
Fie setul de date de mai jos:
| Student | Study hours | Grade |
|---|---|---|
| 1 | 1 | 5 |
| 2 | 2 | 6 |
| 3 | 3 | 7 |
| 4 | 6 | 9 |
| 5 | 7 | 10 |
Calculează media și eroarea în funcție de ultima coloană.
În funcție de ce valoare t a coloanei Study hours vom împărți datasetul astfel încât să reducem eroare cu valoarea maximă posibilă?
Soluție aici
Arbori în sklearn
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
from sklearn.tree import DecisionTreeClassifier, plot_tree
clf = DecisionTreeClassifier()
clf = clf.fit(X_train, y_train)
plot_tree(clf)
[Text(0.5, 0.9166666666666666, 'x[2] <= 2.35\ngini = 0.665\nsamples = 120\nvalue = [39, 37, 44]'),
Text(0.4230769230769231, 0.75, 'gini = 0.0\nsamples = 39\nvalue = [39, 0, 0]'),
Text(0.46153846153846156, 0.8333333333333333, 'True '),
Text(0.5769230769230769, 0.75, 'x[3] <= 1.75\ngini = 0.496\nsamples = 81\nvalue = [0, 37, 44]'),
Text(0.5384615384615384, 0.8333333333333333, ' False'),
Text(0.3076923076923077, 0.5833333333333334, 'x[2] <= 4.95\ngini = 0.18\nsamples = 40\nvalue = [0, 36, 4]'),
Text(0.15384615384615385, 0.4166666666666667, 'x[3] <= 1.65\ngini = 0.056\nsamples = 35\nvalue = [0, 34, 1]'),
Text(0.07692307692307693, 0.25, 'gini = 0.0\nsamples = 34\nvalue = [0, 34, 0]'),
Text(0.23076923076923078, 0.25, 'gini = 0.0\nsamples = 1\nvalue = [0, 0, 1]'),
Text(0.46153846153846156, 0.4166666666666667, 'x[3] <= 1.55\ngini = 0.48\nsamples = 5\nvalue = [0, 2, 3]'),
Text(0.38461538461538464, 0.25, 'gini = 0.0\nsamples = 2\nvalue = [0, 0, 2]'),
Text(0.5384615384615384, 0.25, 'x[2] <= 5.45\ngini = 0.444\nsamples = 3\nvalue = [0, 2, 1]'),
Text(0.46153846153846156, 0.08333333333333333, 'gini = 0.0\nsamples = 2\nvalue = [0, 2, 0]'),
Text(0.6153846153846154, 0.08333333333333333, 'gini = 0.0\nsamples = 1\nvalue = [0, 0, 1]'),
Text(0.8461538461538461, 0.5833333333333334, 'x[2] <= 4.85\ngini = 0.048\nsamples = 41\nvalue = [0, 1, 40]'),
Text(0.7692307692307693, 0.4166666666666667, 'x[1] <= 3.1\ngini = 0.5\nsamples = 2\nvalue = [0, 1, 1]'),
Text(0.6923076923076923, 0.25, 'gini = 0.0\nsamples = 1\nvalue = [0, 0, 1]'),
Text(0.8461538461538461, 0.25, 'gini = 0.0\nsamples = 1\nvalue = [0, 1, 0]'),
Text(0.9230769230769231, 0.4166666666666667, 'gini = 0.0\nsamples = 39\nvalue = [0, 0, 39]')]
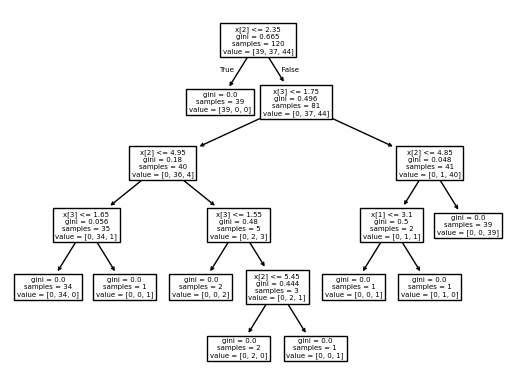
Algoritmul tinde să producă modele overfit, de aceea este recomandat pruningul pe arbore.
Pruning
Pruningul este metoda de a scoate ramurile care nu aduc informație relevantă dintr-un arbore. Există 2 categorii de Pruning: pre-pruning și post-pruning:
- Pre-pruning (sau early stopping)
Se referă la oprirea algoritmului înainte de a produce frunzele care conțin puține sample-uri. Asta înseamnă că îl oprim atunci când eroarea nu mai scade cu valori semnificative de la o iterație la alta. Dacă îl oprim prea devreme putem avea un model underfit, dar salvăm mai mult timp decât dacă am genera toate ramurile pentru ca după sa începem sa le tăiem.
Hyperparametri utilizați: max_depth, min_samples_leaf, min_samples_split
- Post-pruning
Este cel puțin la fel de eficient ca pre-pruningul, dar demonstrabil matematic. Algoritmul implică să tăiem frunze din arbore până minimizăm eroarea pe setul de test. Nu facem asta de la început deoarece riscăm să oprim algoritmul înainte de a crea o întreagă ramură utilă.
Hyperparametri utilizați: cpp_alpha
Exercițiul 5
Antrenați un model de Naive Bayes și un Decision Tree pe problema de aici: https://judge.nitro-ai.org/cram-school/cram-school-training-1/problems/3/task
Cum influențează algoritmul folosit felul în care trebuie preprocesat setul de date?
Exercițiul 6
Citește paperul original: link
De ce Impuritatea Gini și Entropia sunt limitate între [0, 0.5] respectiv [0, 1] ?
Când vrem să folosim fiecare dintre cele 2 modele?
Răspuns